How to use GIS for Machine Learning

By Thomas Sitbon for Preligens, 20/06/22
A guide to where to source data and how to describe images for training
In our 2 previous amazing articles: How we built an AI factory — Part 1 and How we built an AI factory — Parts 2&3, we wrote about how we built a proprietary framework used by all AI teams across the company.
In order to understand the full cycle of creation of an algorithm, I will now explain two main pre requisites in this article:
- Where to source data in a simple and automated way?
- How to better describe the images for training?
What are the data requirements for building AI detectors? — The case of geographic data
Global data diversity
To develop a machine learning algorithm specialized on geographic data, a large variability of data is required in terms of :
- geographical zones : weather conditions (snow, clouds), urban or desertic areas, latitude and time of the day (shadows)…
- Sizes and shapes of the observables to detect (different models of aircraft, civilian, military…)
Data Localization
One other requirement is to also have a great variety of objects in different geographical contexts (for example aircrafts in parkings, runways, maintenance areas).
An aircraft can have different shapes, colors or positions but it will still belong to the same category and therefore, it will have to be classified in the very same class.

Complexity of geographical areas and observable with various forms — Source : 2022 Copyright Maxar Technologies
Our challenge: detect specific objects on all geographical areas around the globe
The objective is to be able to quickly set up an algorithm to detect a determined object on all geographical areas of the globe.
In order to do so, a data scientist will need to have access to:
- The most accurate geographic database possible
- A variety of quickly selectable images: a minimum of 5,000 to 10,000 images
- A specific description of the images that can be used as a train or test base for the Machine Learning (ML) teams
Without those tools and this enriched database, it would be very difficult — not to say, impossible — to find the right images to build an algorithm.
How else would a data scientist find the images he needs to improve the algorithms he is working on ?
In this article, we take the example of building a database of satellite images including the most heterogeneous aircrafts models across the globe.
This training database will be used by ML teams to build best in class algorithms.
The tools we use:
- Libraries commonly used with Python: geopandas, pandas, and shapely.
- PostgreSQL database (for their PostGIS extension)
First step: Building a geographic database
Where can aircrafts be found?
FINDING: Finding the location of observables can be a tedious and time consuming task. We have chosen to retrieve a large number of images that contain a wide variety of observables.
SELECTING: To select the images containing aircraft, we rely on open source data, for example OurAirport, OSM (OpenStreetMap), etc.
EXTRACTING: The extraction of OSM data has been facilitated by ImpOSM. It is an importer of OpenStreetMap data. It reads the files and imports the data into a PostgreSQL/PostGIS database.
MERGING: We have developed a process for merging OSINT (Open Source Intelligence) data followed with data quality control where we remove duplicate sites, data entry errors, etc.
As a result, we have created a database of tens of thousands of airports distributed on the surface of the planet. These sites are located by their latitude and longitude.
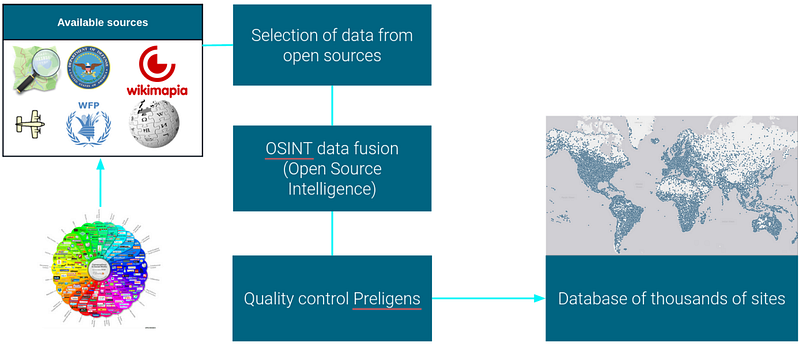
How we select sites of interest — Source : Preligens
Building a site database
However, building such a database is not enough. With the help of Open Source data, we added descriptive metadata for each airport: name, civilian or military, operational, size, function, country, number of runways, available equipment, etc.
With this information, the selection of site is more precise and of better quality.
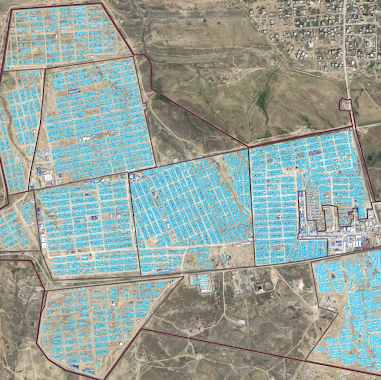
Using some OSINT databases, we can get an accurate overall footprint of the site, as well as specific sub-areas within which our observables can be located : aircraft storage area, aircraft movement area.

We have the Area of Interest (AOI) of each image ! — Source : 2022 Copyright Maxar Technologies
Fig.3 We have the Area of Interest (AOI) of each image ! — Source : 2022 Copyright Maxar Technologies
The last task is the implementation of a descriptive database of all the airports distributed on the earth. We can make SQL queries on the type of site (military or civilian), on its function, its country of origin, etc.
For example, the search for Antonov An-124, can become very tedious. Today, there are only 28 aircrafts in flying condition. With a database selection : country=ukraine and russia ; military=yes ; material=an124
4 sites are selected, this selection allows to greatly improve the detection of uncommon observables.

Selection of rare observable, example on the An-124 — Source: 2022 Copyright Maxar Technologies / detections by Preligens
Second step: Acquiring satellite imagery
Obtaining a quality dataset in a minimum of time is a real challenge. The selection of images can become a real puzzle. The challenges are numerous: diversity of images, duplicate data, homogeneous separation between the test database and the train database, storage of information in the database, data normalization, etc.
Preligens has developed an automated image recovery process with major image providers.
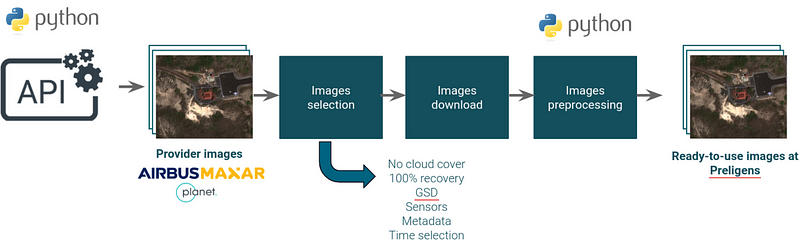
Image recovery and normalization pipeline — Source : Preligens
Access to images
With the increase in the number of earth observation satellites, it’s possible to have several very high spatial resolution images several times a day. At Preligens, we have chosen to partner with the best earth observation companies: Airbus, Maxar and Planet. The use of these images has been automated through several APIs developed by the image providers :
- Maxar : ARD API
- Airbus : OneAtlas API
- Planet : Planet API
The use of APIs makes it possible to simplify the selection of images based on very fine criteria :
- Sensors
- Temporal frequency
- Number of images per area
- Incidence angle
- Sun elevation
- Cloud cover
- GSD
In a few hours, it’s possible to recover several thousands of images, a few km² each, over the last 15 years and around the whole earth.
The data normalization step
Each image provider uses a different image format, metadata and file structuring. The normalization step is therefore key. The only objective is to normalize the data before it is used by machine learning algorithms.
For example: the file format, the pansharpening, the number of spectral bands or the encoding of the image.
Third step: description of the images
Introduction : Why describe a satellite image?
Choosing the right train and test dataset is a complex process. In order to help AI engineers to choose their datasets efficiently, we provide 2 categories of information:
- Image metadata
- Descriptive metadata of images
Image metadata
Each satellite image has metadata provided by the image providers : view angles, sun elevation, sun azimuth, pixel resolution, uuid, captured at, etc. This metadata is available with an API call or in a file associated during the download with a non-standardized format (xml, json, txt, etc.). The recovered information is stored in a database.

Image metadata — Source : Preligens
Descriptive metadata of images
Automated description of an area of interest is a simple exercise if you know where to search for additional data.
ML teams need 4 important details :
- Snow cover
- Land cover
- Aerosol density
- Localisation

Descriptive metadata to select specific datasets, exemple : desert images — 2022 Copyright Maxar Technologies
We solved this challenge by using open source data on a global scale:
- Land cover : Copernicus Global Land Cover Layers — PROBA-V (source : Copernicus — ESA)
- Terra/Aqua Snow Cover Daily Global 500m — MODIS (source : NASA)
- Copernicus Atmosphere Monitoring Service (CAMS) — (source : ECMWF)
- Global Administrative Unit Layers (source : FAO)
For more details, the recovery of this information is fully covered in a previous article: Improving the description of satellite images using GIS data here.
Fourth Step: Data labeling — Without labeling, there is no machine learning
Construction of an ontology and a classification of geographic objects
To obtain homogeneous observables between classes, we built a descriptive ontology of observables. This ontology was developed with intelligence experts. For example, we described a hundred homogeneous classes of aircraft. Each observable is described in detail (length, width, type, function, etc.).
These descriptions allow the annotation teams to understand which observable to classify.

From ontology to labeling — Source : Preligens
Flexible and internal labeling application
There are several dozen companies that can label observables for machine learning. However, very few have implemented geographic data entry tools. At Preligens, we are fortunate to work with intelligence experts. We have developed an ontology of several hundred classes of observables. Each entity is clearly described with an annotation guide describing: the observable, the characteristics of specific observations and the environment describing the observable.
For more than 4 years, we have implemented a flexible and robust internal application that allows us to label data, classify them and set up a quality check.
The quality check is mandatory in the development of a machine learning dataset.
We have made the choice, a long time ago, to check all the labeled data several times and in a random way. We added an automatic error detection phase using geospatial tools and scripts: registration error, incomplete polygon, impossible classification, etc.
Conclusion
At a time when machine learning is taking all its place and importance in the observation of the earth, we note that Geographic Information Systems are one of the many elements which allow the construction of these algorithms.
To go further on building an AI factory, I strongly advise you to read this enlightening article : How we built an AI factory — Part 1 here
Read all our Preligens Stories on Medium here.
![Est-il difficile pour une IA de détecter des navires sur des images satellites ? [EN]](/sites/default/files/2021-04/captain.png)
![Amélioration de la performance de la détection d'objets par l'assemblage sur l'imagerie satellitaire [EN]](/sites/default/files/2021-04/1_3.png)