AI factory — Partie 1 [EN]

08/31/2021 by Marie-Fleur Sacreste
Most data scientists and communications around AI focus on performances and how to get the best F1 score or mAp. However when developing AI enabled systems (especially on premise like Preligens) performances are key but they are only the tip of the iceberg.
The hardest technical challenge to overcome is to take this performance to production, iterate fast enough to improve the product with an industrial approach.
Growing from a 1 to a 70 people tech team, all working on deep learning and artificial intelligence, in less than 4 years — our first employee arrived in July 2017! — we faced production problems daily!
How to scale teams and technology fast enough ?
How to scale and still improve algorithms and ensure they are reproducible, maintainable and standardized for the whole company and products ?
In this article we explain how we managed to industrialize the creation of new detectors and made the integration of state of the art models easy to use and deploy even when products are deployed on premise, sometimes even on classified environments.
Our strategy :
- Focus on research and development : A dedicated R&D team to test and integrate state of the art research into our models, in test but also in production.
- Create a unique framework : our AI factory. A toolbox for our AI teams, helping them to create in a short period of time high accuracy and reliable detectors, to industrialize AI algorithms creation.
- Dedicate a team to this framework : our AI engineering team. A third of our AI engineers are working on the framework. This is a multidisciplinary team, from Machine Learning engineers, to computer vision researchers, architects, fullstack developers and devOps.
Our AI factory makes it possible to :
Part 1 — Scale our company ensuring quality and reproducibility of our detectors: More than a dozen people are working on the framework full time with an expected growth of 60% in 2021.
Part 2 — Create the best possible performing models : Never less than 95% and up to 98% accuracy with State of the Art model architecture.
Part 3 — Shorten the cycle between research and production: With our AI factory, once an innovation has demonstrated its potential, it takes less than 3 months to go from our research team to the client premise.
This first article focuses on how we built standard, reproductible and scalable deep-learning algorithms while in production
Part 2 and 3 will be explained in the next stories.
Standardize, reproduce and scale … while in production
The main challenges to overcome for an AI company when scaling their teams are:
- Standardisation: When onboarding new data scientists they come with their own experience, tools. This can lead to discrepancies in quality in the same product. Stability of our algorithms in production is essential.
- Reproducibility : Any new team working on an existing algo to improve it must understand the latest results before starting.
When we started our activity, we quickly realized that we were facing a common problem: time to production was long (up to 6 months) and it was hard to reproduce and standardize experiments. Moreover lots of data scientists were using different frameworks. These issues are not uncommon, every company working with data faces them. What was unusual was the speed at which we were growing, the technology used and the deployment on premise, on classified environments.
At Preligens, we are using deep learning to create AI-enabled software that are deployed in defense and intelligence agencies around the world. The problems we tackle are tough, very tough, and the technological context is even more challenging. For example we train algorithms with commercial data that are deployed on a classified system, usually we are not even allowed to access the data. Our goal is to reach more than 95% performance. Using simple off the shelf algorithms (Yolt, unet etc..) is not an option; we need to package complex ensembled detectors with large amounts of pre and post processing.
For example, our Aircraft detection algorithm on satellite images combines custom Res-unet with Retinanet and no less than 5 proprietary post-processing tasks to achieve aircraft identification on more than 100 classes.

Aircraft detection example. Source : Preligens

Helicopters detection example. Source : Detection by Preligens, Satellite images by Maxar
More post-processings can be used to increase our outputs, for example in our road detector where 8 of them are used to make this mapping possible :
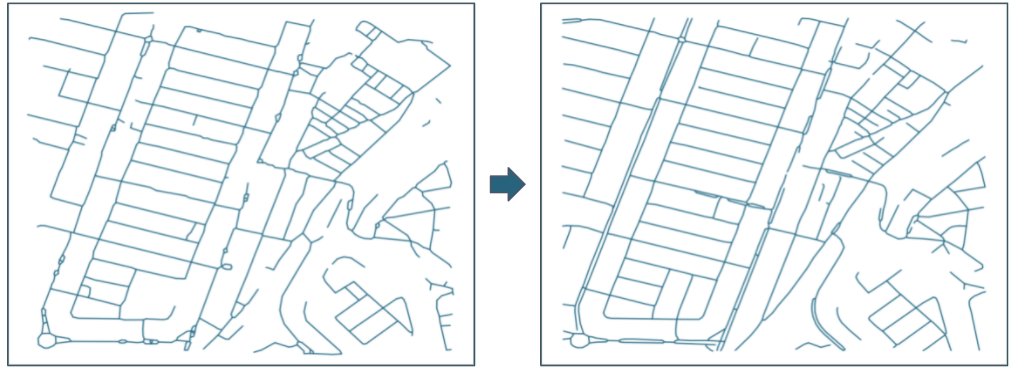
Impact of post processing. Source : Preligens
And these are ones of the simplest objects we are trying to detect. Just think how complex it could be when we try to identify Missile launcher from Armored combat vehicle on commercial 30cm resolution images…
Consequently we benchmark several tools to try to apply them to our use cases and none of them were specialized or mature enough to allow the flexibility and power we needed.
Most AI frameworks focus indeed on simplier Machine Learning application or more “mainstream” deep learning AI tasks (autonomous vehicles, smartphone images) or are better suited for team <15 people. This is why we ended up creating our own framework, our AI factory.
To tackle these challenges, we created our AI factory :
A unique framework, used by all AI teams
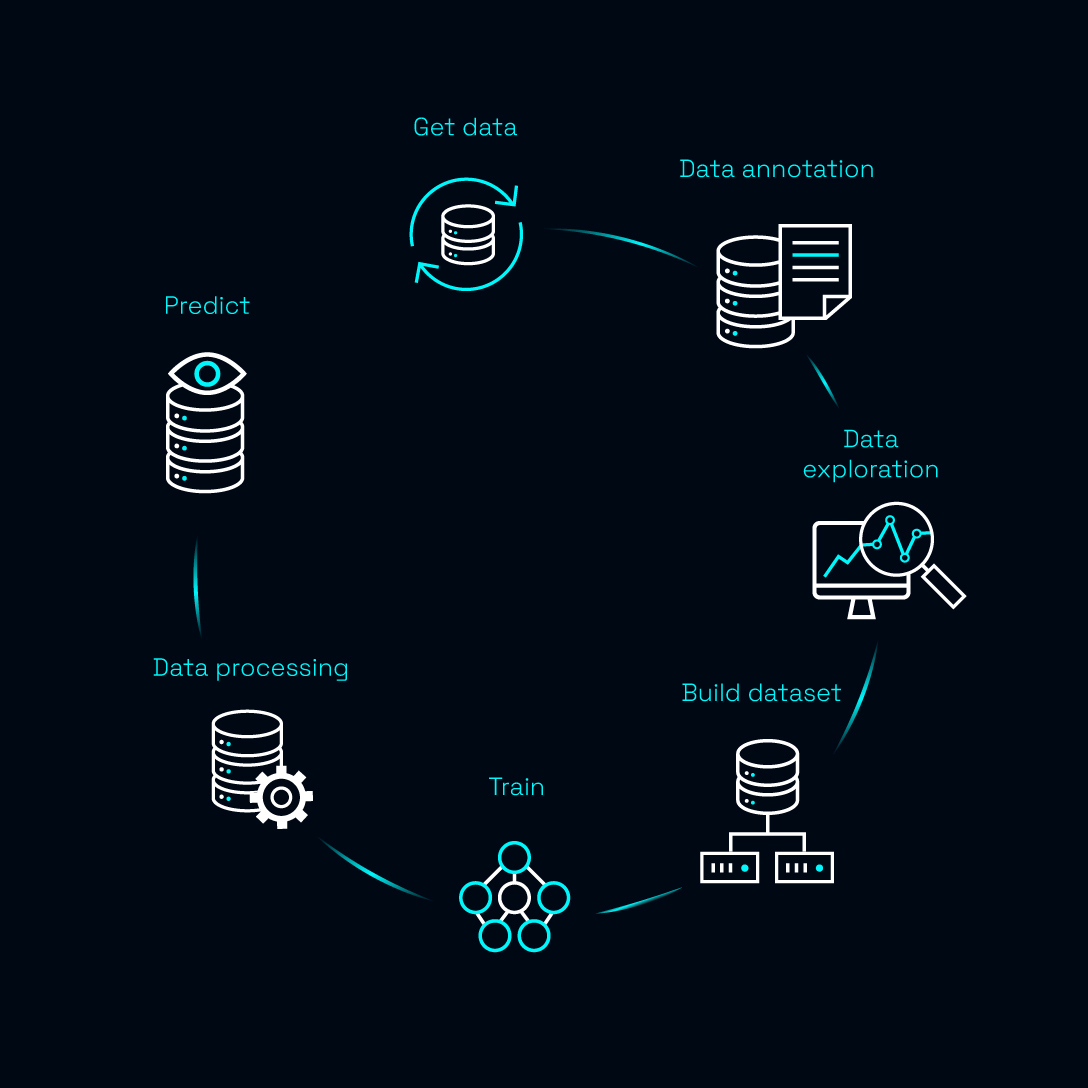
This framework covers 5 of the 7 steps of AI algorithm development and makes it possible to reach the level of performance needed for our applications.

Source : Preligens
- [Data exploration] to select the best data for training and testing
- [Data processing] to make the data compatible with our algorithms
- [Build dataset] to create a training dataset, just like the ingredients for your 4 star Michelin recipe
- [Train] to design of the architecture of the model and to train this model
- [Predict] to predict results and evaluate the model.
And we added a bonus step:
[Deployment in production] This step, often overlooked is fundamental to us as our products are deployed in production
Our AI Framework covers a total of 6 steps (5 + the bonus), our code library is built upon Tensorflow and Keras and the MLOps platform we use is Valohai.
Being robust on these 6 steps is key but to be really robust we had to master all steps.
The first two steps “Get Data” and “Data Annotation” are covered in house by our data stack team. Indeed, our AI factory could not perform well if the quality of the data we use and its annotation was not perfectly done. The way we achieved high quality for data annotation will be covered in another article.
An entirely configurable framework
For each step, teams will configure different yaml files that give them the flexibility to find the right settings for the specific use case they are working on. Our framework gives massive possibilities for each detector : more than 12000 configurations are possible. Obviously they won’t be able to compare all configurations ! So the complexity for them will lie on the right selection of the few architectures and settings to test and compare.
We then give them a way to compare thanks to Valohai and Kibana dashboards. They can easily validate direction and focus on the right solution that will allow reaching the best performance depending on our client’s use case.
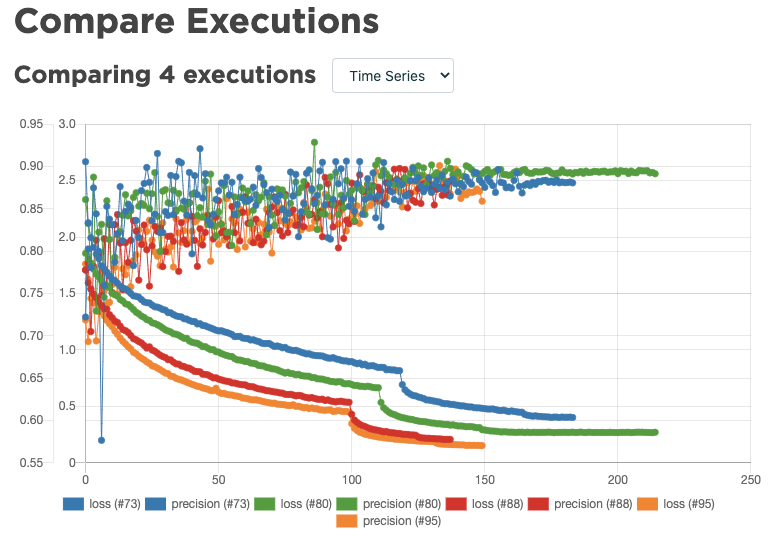
Credit : Valohai and Preligens
Our AI factory also provides an easy way to perform a running point search: a prediction over different sets of parameters in a yaml file to pick up the best set, thus fastening experimentation. It allows teams to explore four times more possible configurations in half the time we needed before.
Our framework with the use of yaml files allow them to integrate state of the art model architecture.
One team is in charge of its quality : multidisciplinary profiles, from ML engineer, to computer vision researchers, architects, fullstack developers and devOps.
A collaborative framework
When several people work on the same code library, which is doomed to happen when the team grows, extra care must be taken to keep it clean and fully operational. This is why we use continuous integration: including making unit tests to ensure that every single function works correctly, and running functional tests for the whole code.
So why is our AI factory a game changer in our organization now ?
Simply because we can have more than 10 detectors deployed in production, all with high accuracy and reliability no matter what object to detect. Every 6 weeks, all teams have the ability to release the enhancements of their detectors in production. This represents an impressive average of 10 training and 5 running point searches per week over each 6 weeks release.
But this is not the only reason! ! Parts of our framework are opened to contributions from other teams. Specialists review these contributions, allowing teams to increase their coding skills and good practices. Last but not least, our CI/CD makes the last check to ensure top quality of all new features!
A complete documentation
Documentation is most of the time a part that is never prioritized. When developing a complexe framework that is evolving every month and used by dozens of data scientists, clear documentation is key.
Our documentation is splitted in three categories:
- A clear onboarding explaining to all Preligens employees our missions and goals.
- Tutorials explaining step by step how to use our factory for new data-scientists
- Developer documentation synchronized with our code to explain how to use new features
Next story (Part 2) will explain how we create super performing models…
Cover Image source : VIAVAL TOURS / Shutterstock.com