Contact form
Your request has been sent.
Please enter your name
Please enter your email
Please enter a correct email address
Please enter your company name
Please enter your message
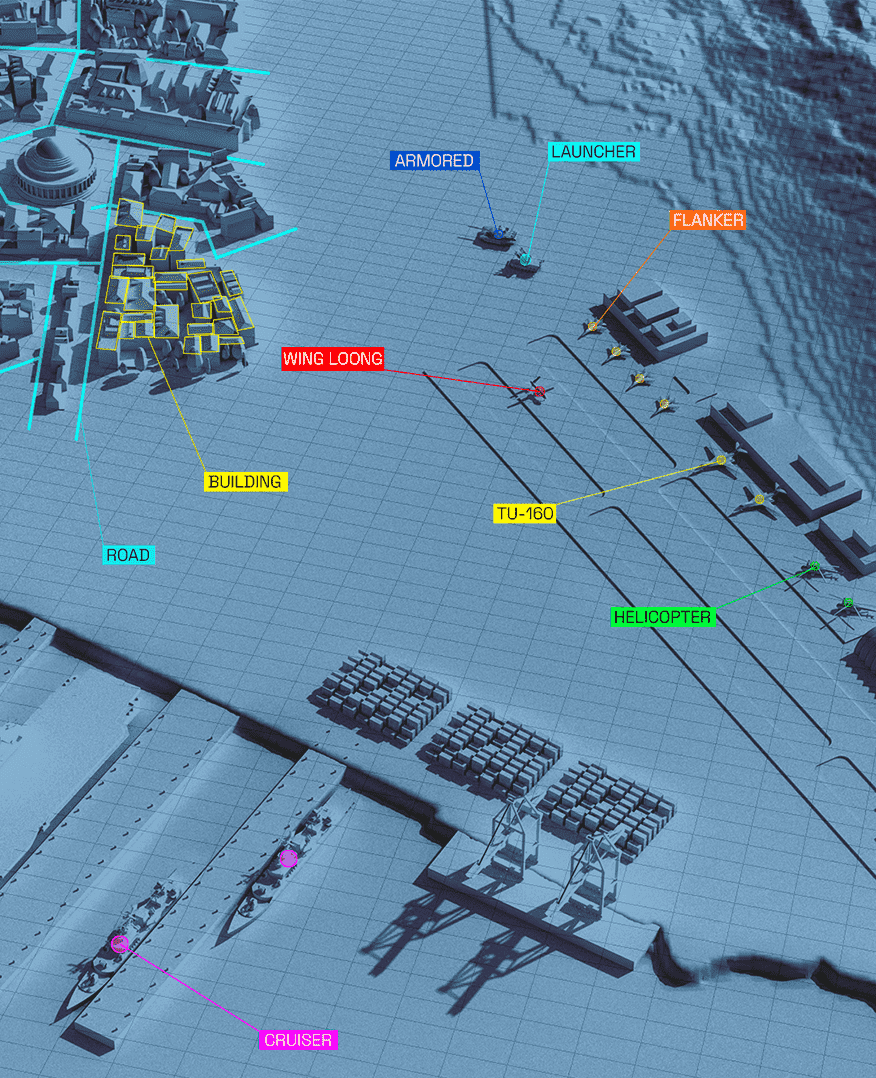
Latest news

T&C #15 - 5 highly challenging detections performed by Preligens AI
T&C #15 - 5 highly challenging detections performed by Preligens AI
![[PRESS RELEASE] Preligens to develop a foundation model for geospatial data](/sites/default/files/2023-12/jean-zay-annonce-01.jpg)
[PRESS RELEASE] Preligens to develop a foundation model for geospatial data
[PRESS RELEASE] Preligens to develop a foundation model for geospatial data
![[DETECTION] China: Detecting infrastructure work in Sanya naval base](/sites/default/files/2023-04/YulinSanya-port.gif)
[DETECTION] China: Detecting infrastructure work in Sanya naval base
[DETECTION] China: Detecting infrastructure work in Sanya naval base
Testimonials from our customers


“Those tools enable us to detect threats we wouldn’t have spotted to accelerate the intelligence cycle”
Direction du Renseignement Militaire (DRM)
CF3I Commander


“ The Preligens software is a force multiplier for the NIFC and will allow us to more efficiently process large amounts of imagery data in support of our mission. An automated solution is critical in order to best utilize that data and free up capacity of our analysts to perform the more detailed analysis of the activity. ”
NATO Intelligence Fusion Center (NIFC)
NIFC Commander


"Intelligence is the fuel of operations, as such Preligens' technologies are very interesting for us".
Chef d’Etat Major des Armées (CEMA)
Général Thierry Burkhard


“We need to leverage any available sensor with tools that securely analyze, collect and disseminate data.”
Supreme Allied Commander Transformation (SACT), NATO
General Philippe Lavigne


"The Preligens solution brings real operational maturity with a very significant time saving on the registration of roads and buildings. Preligens detections are of high quality thanks to their regularity. This is a major and concrete example of innovation through artificial intelligence that changes our day-to-day operations."
Etablissement géographique interarmées (EGI)
Amelie Molle, Technical Director


“It has been a complimentary active learning project where the military and ourselves have learnt from the research alongside Preligens”
Defence Science and Technology Laboratory (DSTL)
DSTL Technical Advisor


"Be one step ahead. Preligens introduced me to its artificial intelligence tools for processing intelligence for the Navy. These tools multiply our technical and human potential and are of major operational interest."
Chef d’Etat Major de la Marine (CEMM)
Admiral Pierre Vandier


Meet Our
Ambassadors


I joined Preligens to do a PhD in NLP and Network Analysis for geopolitical events' detection. During my first months aboard, I took part in diversifying the expertise of Preligens as a data scientist in the Product Team working closely with our Geopolitical Team. I gained new skills by integrating a new stream of data to the product while building my thesis project. Preligens is a great place to do research as innovation is part of its identity and I am proud to take part in creating a new industry.
Edward
NLP Expert


I joined Preligens to build new object detection algorithms and deploy them in production. Working in 3-person squads, using very high-resolution satellite images and state-of-the-art Deep Learning algorithms is very exciting on a daily basis. Since my arrival in April 2020, I participated in the delivery of six algorithms, used operationally in the software.
Aurélia
Lead Deep Learning Scientist


I joined Preligens in 2019 within the software team to build our applications related to our IMINT product SCube. I was one of the first members of this team, which allowed me to assist to the rise of the team and our product. I was able to participate in the development of our resilient, powerful and reliable product with a rising team of tech enthusiasts.
Clément
Developer


I joined Preligens with the objective to develop the business expertise part in the SIGINT branche. Everyday, I do research and propose new data from commercial sensors. I bring to the table the knowledge acquired from my past experience in the military sector. Preligens is endowed with an exceptional engineering potential, which allows the company to provide cutting-edge solutions to our customers. The search for innovation in this new digital world is the DNA of our team.
Loïc
Expert SIGINT (Signal Intelligence)


I joined Preligens to build the recruitment team, and deploy processes. By the end of my first week, I had implemented a new Applicant Tracking System and was starting to train the managers. This capacity to empower people is probably Preligens’ most important perk to me, enabling people to have a tangible impact in a world-changing organization.
Amaury
Talent Acquisition Manager


I joined Preligens (then still Earthcube) as the first employee. At the time, the company consisted of the two founders, Arnaud & Renaud, 4 interns, and me. As the company evolved, my responsibilities have increased, the teams split, the habits and processes evolved. However, the company culture that pushed me to join has stayed the same, with a strong attention towards the well-being of the employees. As Head of AI Research, I encounter new exciting challenges every day and I have an amazing team to tackle them!
Tugdual
Head of R&D


After my first job in a contractor company, I did a 180 ( or 360) and went back to school because I wanted to learn new skills and discover new things.
Right after my second master's degree, I joined Preligens and I was relieved to discover that just because you finish your academic career doesn't mean you stop learning and being amazed. Every day I learned from a whole new spectrum of skills and knowledge. I guess I could say coming to preligens "you get what you bring". Mine was the will to discover new things.
Hélène
GIS Developer


Chloé Folliot
Annotation Operator


Virginie Moizan
Head of Operations - Data division in Rennes
![The [artificial] intelligence newsletter](/sites/default/files/2021-09/logo%20roberta%20copie_1.png)