Boosting object detection performance through ensembling on satellite imagery

How image analysts and object detection algorithms can benefit from the latest advances in ensembling techniques.
11/17/2019, by Matthieu LIMBERT
In Machine Learning (ML) projects, the last percentages of performance are the most difficult and time-consuming to reach.
The reason behind that is that they are related to the hardest cases.
Vehicles in the shadow & vehicles partly hidden by trees
If we take the case of civil vehicle detection on VHR (Very High Resolution) satellite images, some hard cases could, for instance, be objects that look similar in both desert environments (small trees, rocks and buildings) and in working areas (containers). It can also be bad quality images, partly hidden vehicles (by buildings, clouds or vegetation), vehicles in the shadow or even in the snow.
At Earthcube, many of our clients rely on satellite imagery analysis and need very high-performance algorithms. So the last percentages of performance are also the most important to achieve.
Ensembling as an alternative at Earthcube
To convert a good performance model into a very high-performance model, even an experienced ML team has only two options that are time-consuming: 1) increase the size of the training set by getting more labelled data
2) perform lots of tests to optimize the model architecture and hyper-parameters.
Thanks to the latest advances in the scientific community and our last developments, ensembling has now become, at Earthcube, a new alternative that is less time-consuming yet still very efficient for satellite imagery. It is currently used for civil vehicle detection and other observables.
What is ensembling?
In our case, ensembling is a technique that aims to maximize the final detection performance by fusing individual detectors.
While rarely mentioned in deep-learning articles applied to remote sensing, ensembling methods have been widely used to achieve high scores in recent data science competitions, such as Kaggle. The few remote sensing articles mentioning ensembling mainly focus on mid-resolution images and Earth Observation applications such as land use classification, but never on VHR imagery for object detection.
The reasons might be that there are various ensembling techniques (it is easy to get lost…), and they all have specific parameters that are hard to optimize to the specific task of object detection on satellite images. Indeed, most of them have been only tested and optimized on the classification task for standard image datasets such as CIFAR-10 and CIFAR-100, which is a very different use case.

If the ensembling technique is well selected and its parameters properly optimized to the use case, this can lead to a large performance boost. Nevertheless, it usually comes with a downside: most of the ensembling techniques need several predictions, which increases the overall computation time.
Selection of the ensembling techniques
All ensemble learning methods rely on combinations of model variations in at least one of the three following spaces: training data, model space, and prediction space.
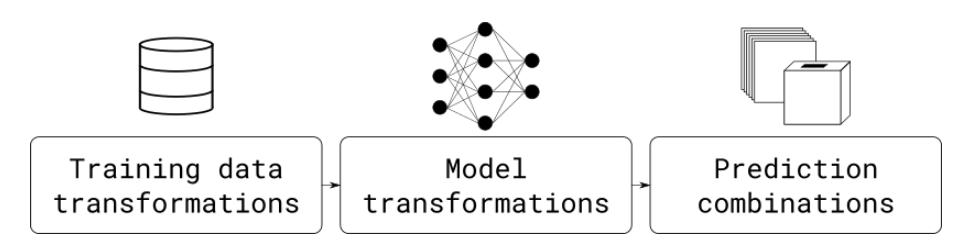
In the following, ensembling techniques will be selected making the assumption that a high-performance model has already been developed and needs to be improved spending reasonable development time.
Training data
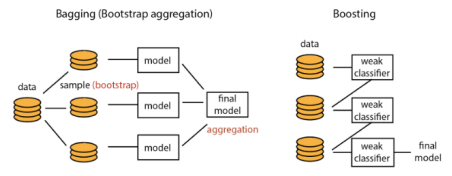
Boosting [1] and Bagging [2] are the main techniques.
Boosting consists in training different models in series, where each model tends to correct the errors of the previous one. This technique is dedicated to weak models and not suited to deep-learning.
Bagging generates new sub-datasets (by extracting random sub-samples from the original one), trains one model per sub-dataset, and fuses their predictions. This technique looks promising but is hard to implement and time-consuming: the model architecture needs to be re-optimized on the smaller sub-datasets.
Model space
Recently, several techniques have emerged to generate variations of the original model (called snapshots) during the training to substantially increase the performance.
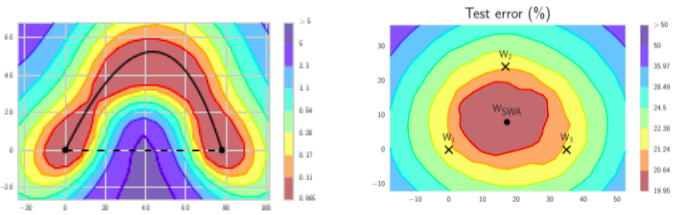
Snapshot Ensembling (SSE) [3] cyclically modifies the learning rate so that the model reaches several local minima during the training. A snapshot is taken for each of the local minima and their predictions are fused. Nevertheless, this increases substantially the training time, it is thus not well suited to our very large training sets.
Fast Geometrical Ensembling [4] also modifies cyclically the learning rate to move the model along a low loss path in the weights space and generates snapshots with similar performances but different behaviors. It can thus be used as a fine-tuning and solves the training time issue of SSE.
Stochastic Weights Averaging (SWA) [5] is very close to FGE, but instead of fusing the predictions of the snapshots, the model weights are fused to generate a more robust unique model. So that the computation time at prediction is not impacted.
Prediction space
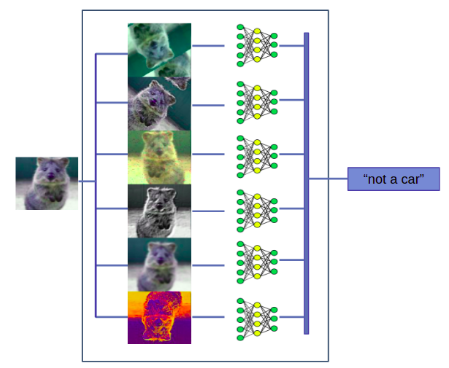
Different techniques exist to fuse the predictions. The simplest technique is voting: it is easy to use in production. The downside is that using a low-performance individual model (even if very efficient on one specific type of the input data) will decrease the overall performance.
Stacking [6] solves this issue: a new model is trained and takes in input the predictions of the individual models. Then, it can learn the specificity of each of the individual models, so even weak models can participate to increase the overall performance. Nevertheless, the fusion model needs to be re-trained if one of the individual models is modified, so this technique is hard to use in production.
Other techniques generate different predictions of the exact same model: Test-time Augmentation (TTA) [7] & Bayesian dropout [8]. To generate the predictions to fuse, the first one modifies the input image at prediction time (rotation, translation, intensity, etc.), while the second one disables a set of randomly chosen neurons in the models. Those two techniques are promising and don’t need any new training.
Selected techniques
TTA, Bayesian Dropout, FGE and SWA are very promising and do not involve large development time. Based on our experiments, TTA and Bayesian Dropout provide larger performance boosts when combined, so we finally selected three techniques: TTA & Bayesian Dropout combined, FGE and SWA.
Application to vehicle detection in the desert
The desert environment is a great use case to evaluate these techniques. Indeed, it is very painful for image analysts to look for very small civil vehicles in very large areas. In addition, a lot of objects such as small trees, rocks and buildings look similar to vehicles and lead to false positives.

Original model
We applied the selected ensembling techniques to a very high-performance model that has been developed at Earthcube thanks to a lot of architecture and hyperparameter tests, and a very large training set. The model has been trained on+330K vehicle examples in very diverse environments (urban, vegetation, coastal, desert, etc.) and different conditions (snow, aerosols, summer, etc.).
Testing set
In order to evaluate those three selected ensembling techniques in the desert environment, we have built a very large testing set: a size of 603 km² with 4 vehicles per km², gathering all types of deserts around the globe and different conditions (summer, snow, aerosols, etc.).
Result of the tests
We can observe that both TTA & Bayesian Dropout combined in one hand, and FGE on the second hand provide very large performance gain (respectively -47% and -25% of false positives). Also, SWA provides substantial performance increase (-10% of false positives) without increasing the computation time during prediction, which is very valuable in cases where there is a time constraint.
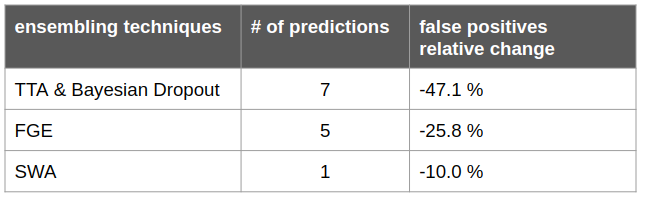
Regarding computation time, performing N predictions does not necessarily mean that the prediction time is multiplied by N. For instance, in the case of TTA & Bayesian Dropout, we optimized the implementation so that 7 predictions can be performed by multiplying the time by only ~3.
By looking at the images, we observe that the three techniques increase the performance by decreasing the number of false positives on objects that look similar to vehicles.

Original image and ground truth (in yellow)

Detection of the original model (blue) — some false positives on small buildings and trees

Detection of the original model with TTA & Bayesian Dropout (green) — only one false positive remaining
Conclusion
Ensembling has become a new efficient tool at Earthcube to increase models’ performances on satellite imagery. This use case illustrates how ensembling can bring value to both image analysts and our ML team if the ensembling technique parameters are properly optimized.
Various techniques exist: the one suited to the use case should be carefully selected to maximize the performance while respecting the use case time constraints and ensuring a low complexity of development.
Literature
[1] Jerome H. Friedman. Stochastic gradient boosting. Comput. Stat. Data Anal., 38(4):367– 378, February 2002
[2] Leo Breiman and Leo Breiman. Bagging predictors. In Machine Learning, pages 123–140, 1996.
[3] Gao Huang, Yixuan Li, Geoff Pleiss, Zhuang Liu, John E. Hopcroft, and Kilian Q. Weinberger. Snapshot ensembles: Train 1, get M for free. CoRR, abs/1704.00109, 2017
[4] Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry Vetrov, and Andrew Gordon Wilson. Loss surfaces, mode connectivity, and fast ensembling of dnns, 2018
[5] Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. Averaging weights leads to wider optima and better generalization, 2018
[6] David H. Wolpert. Stacked generalization. Neural Networks, 5:241–259, 1992
[7] Murat Seckin Ayhan and Philipp Berens. Test-time data augmentation for estimation of heteroscedastic aleatoric uncertainty in deep neural networks. 2018
[8] Yarin Gal and Zoubin Ghahramani. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning, 2015